Rob Arbon
Computational Chemist and Data Scientist
Biography
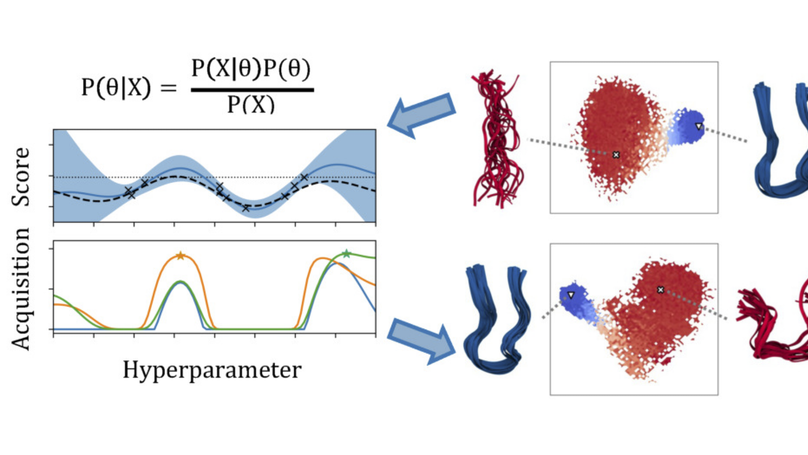
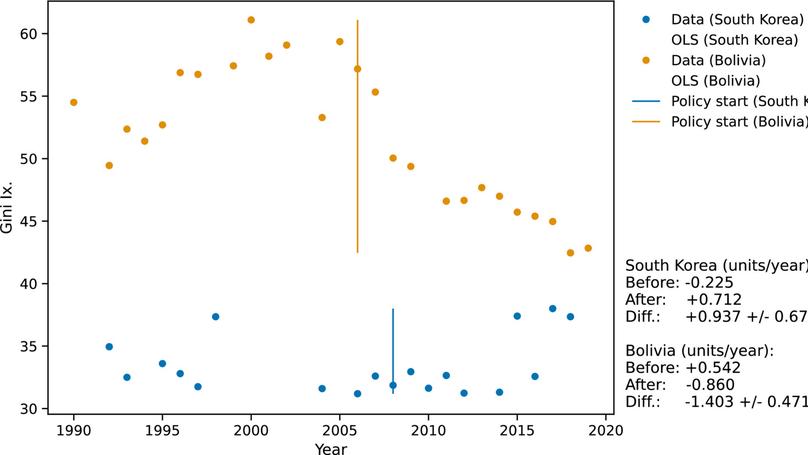
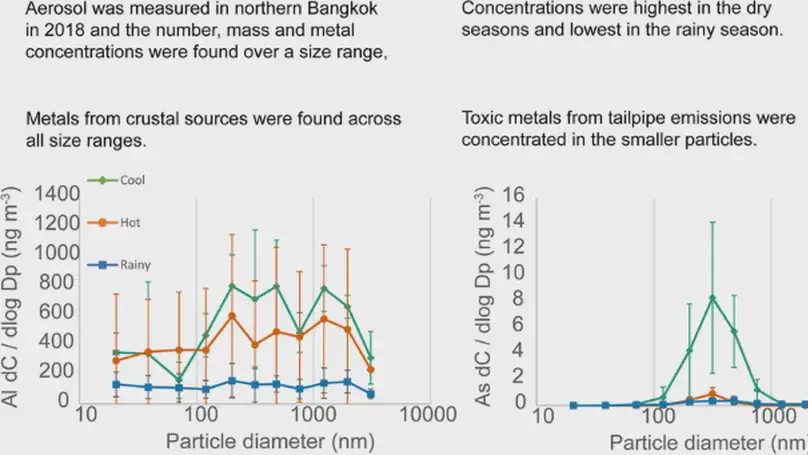
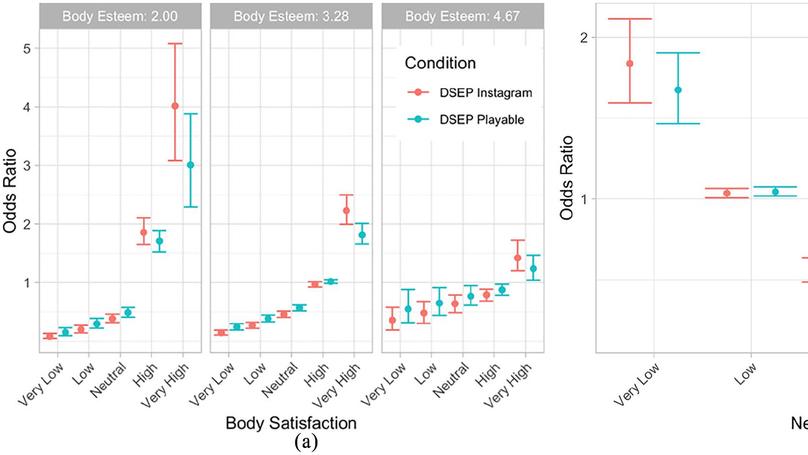
Robert Arbon is a computational chemist and data scientist. Their interests are in using statistics and machine learning methods to understand biomolecular dynamics from computer simulations. In addition, they are interested in novel display of scientific data through both audio and visual media, as well as scientific reproducibility. Their pronouns are they/them.
Download my CV.
Interests
- Software development
- Molecular dynamics and kinetics
- Statistical analysis
- Deep learning
- Bayesian Optimisation
Education
PhD in computational chemistry, 2022
Bristol University
S.M. in applied physics, 2007
Harvard University
MChem chemistry, 2005
Oxford University
Publications
Quickly discover relevant content by filtering publications.